Clickhouse查询优化
虽然clickhouse在大数据量查询速度会比关系型数据库如mysql或者postrges快很多,但还是有很多地方需要去了解和配置,达到提供最低资源获取最大产出
以下内容主要来源于clickhouse官方中文文档
索引设计
关系型数据库设计
主索引采用
B+Tree的数据结构进行快速定位所在行,搜索一个条目的平均时间复杂度为O(log2n),对于一个有1000万行的表,这意味着需要23步来定位任何索引条目额外的磁盘和内存开销
向表中添加新行和向索引中添加条目时更高的插入成本(有时还需要重新平衡
B-Tree)
clickhouse索引
- 按照主键列的顺序将一组行存储在磁盘,一组数据行(称为颗粒(
granule),大小是index_granularity定义配置的,默认8192)构建一个索引条目,即稀疏索引 - 稀疏主索引允许它快速(通过对索引项进行二分查找)识别可能匹配查询的行组,然后潜在的匹配行组(颗粒)以并行的方式被加载到
ClickHouse引擎中,以便找到匹配的行
Clickhouse的颗粒与查询
出于数据处理的目的,表的列值在逻辑上被划分为多个颗粒,颗粒是流进ClickHouse进行数据处理的最小的不可分割数据集,这意味着,ClickHouse不是读取单独的行,而是始终读取(以流方式并并行地)整个行组(颗粒)。
下表的建表语句copy fromClickHouse主键索引最佳实践
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;如下图所示,每8192行数属于一个颗粒
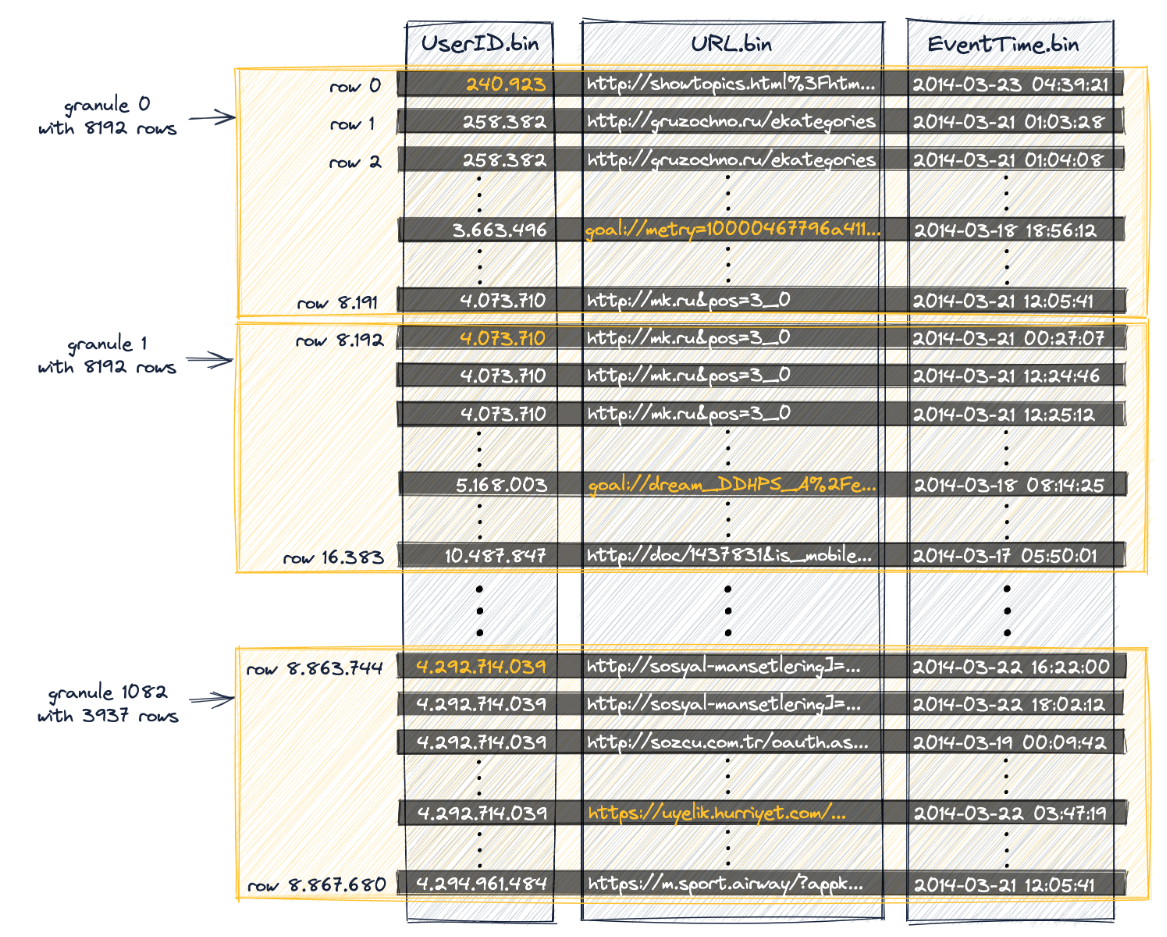
其中主索引是UserID
查询第一阶段:颗粒选择
Clickhouse通过稀疏主索引来快速(二分查找算法)选择可能包含匹配查询的行的颗粒。
查询第二阶段:数据读取
ClickHouse定位所选的颗粒,以便将它们的所有行流到ClickHouse引擎中,以便找到实际匹配查询的行
数据表主键以及排序字段优化
基数概念
数据库中某个表的某个列中不重复行的总个数
对于
mysql等关系型数据库,对于索引列,基数越大,查询效果越好,基数越小,查询效果越差,理想的索引列满足: 基数/实际行=1,比如user表当中如果username是全表唯一的,那么在username上面应用的索引在命中索引前提下查询效果最好
clickhouse表
上表中指定的主键是(UserID, URL),排序键是(UserID, URL, EventTime),注意,排序键指定之后不能更改排序键的值,排序键也不能是空,主键必须是排序键的前缀
字段基数的排列顺序是UserID,URL,EventTime,即UserID去重数量不多(低基数),URL去重之后数量较多,EventTime去重之后数量最多(高基数)
所以最佳的主键设计是(UserID, URL),在Clickhouse的索引文件当中就是先按照相同UserID排序,具有相同的UserID情况下再按照URL排序
主键或者排序键的最佳设计就是保持前缀主键低基数,在这样的情况下会有最少的颗粒流入Clickhouse引擎
实际应用的限制
业务场景中会经常要求按照时间倒序排列的需求,排序键就定义为ORDER BY EventTime DESC ,这样就违反了前缀主键低基数的优化设计了,但是查询的时候不用在sql语句当中显式指定时间倒排了,所以在这种情况下就需要使用到Clickhouse的跳数索引
Clickhouse跳数索引类型
以下文档copy from clickhouse的章节深入理解ClickHouse跳数索引
minmax这种轻量级索引类型不需要参数。它存储每个块的索引表达式的最小值和最大值(如果表达式是一个元组,它分别存储元组元素的每个成员的值)。对于倾向于按值松散排序的列,这种类型非常理想。在查询处理期间,这种索引类型的开销通常是最小的。
这种类型的索引只适用于标量或元组表达式——索引永远不适用于返回数组或
map数据类型的表达式。set这种轻量级索引类型接受单个参数
max_size,即每个块的值集(0允许无限数量的离散值)。这个集合包含块中的所有值(如果值的数量超过max_size则为空)。这种索引类型适用于每组颗粒中基数较低(本质上是“聚集在一起”)但总体基数较高的列。该索引的成本、性能和有效性取决于块中的基数。如果每个块包含大量惟一值,那么针对大型索引集计算查询条件将非常昂贵,或者由于索引超过
max_size而为空,因此索引将不应用。Bloom Filter TypesBloom filter是一种数据结构,它允许对集合成员进行高效的是否存在测试,但代价是有轻微的误报。在跳数索引的使用场景,假阳性不是一个大问题,因为惟一的问题只是读取一些不必要的块。潜在的假阳性意味着索引表达式应该为真,否则有效的数据可能会被跳过。因为
Bloom filter可以更有效地处理大量离散值的测试,所以它们可以适用于大量条件表达式判断的场景。特别的是Bloom filter索引可以应用于数组,数组中的每个值都被测试,也可以应用于map,通过使用mapKeys或mapValues函数将键或值转换为数组。有三种基于
Bloom过滤器的数据跳数索引类型:- 基本的
bloom_filter接受一个可选参数,该参数表示在0到1之间允许的“假阳性”率(如果未指定,则使用0.025)。 - 更专业的
tokenbf_v1。需要三个参数,用来优化布隆过滤器:(1)过滤器的大小字节(大过滤器有更少的假阳性,有更高的存储成本),(2)哈希函数的个数(更多的散列函数可以减少假阳性)。(3)布隆过滤器哈希函数的种子 。此索引仅适用于String、FixedString和Map类型的数据。输入表达式被分割为由非字母数字字符分隔的字符序列。例如,列值This is a candidate for a "full text" search将被分割为Thisisacandidateforfulltextsearch。它用于LIKE、EQUALS、in、hasToken()和类似的长字符串中单词和其他值的搜索。例如,一种可能的用途是在非结构的应用程序日志行列中搜索少量的类名或行号。 - 更专业的
ngrambf_v1。该索引的功能与tokenbf_v1相同。在Bloom filter设置之前需要一个额外的参数,即要索引的ngram的大小。一个ngram是长度为n的任何字符串,比如如果n是4,A short string会被分割为A sh`` sho,shor,hort,ort s,or st,r str,stri,trin,ring。这个索引对于文本搜索也很有用,特别是没有单词间断的语言,比如中文。
- 基本的
高基数字段采用跳数索引优化
高基数字段适合采用bloom filter跳数索引加快查询速度
Bloom filter解释,由一个超长的二进制位数组和一系列的哈希函数组成,二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1,同样是这个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为1,则判断这个元素在这个集合中,若有一个不为1,则判断这个元素不在这个集合中。
更详细的解释参考文档深入理解布隆过滤器以及布隆过滤器Bloom Filter详解
如果想自定义过滤器的输入参数和假阳性概率,可以访问如下地址获取对应的参数布隆过滤器计算网址
调整建表语句如下,
CREATE TABLE hits_UserID_URL
(
-- 加入`Id`字段,采用雪花算法生成
`Id` UInt64,
`UserID` UInt32,
`URL` String,
`EventTime` DateTime,
-- 加入布隆过滤器跳数索引,采用clickhouse提供的默认bloom_filter函数
-- 配置允许假阳性概率为0.001,官方默认值是0.025
-- 概率越小,假阳性概率越低,查询时候会有越少的颗粒发送给clickhouse引擎,所以查询速度更快,但是索引占用的磁盘空间也越多
-- 每个索引块由颗粒(granule)组成, 例如,如果主表索引粒度为8192行,GRANULARITY为4,则每个索引“块”将为32768行
-- GRANULARITY 参数配置为1就可以
INDEX skip_index_url URL TYPE bloom_filter(0.001) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY Id
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;CREATE TABLE hits_UserID_URL
(
-- 加入`Id`字段,采用雪花算法生成
`Id` UInt64,
`UserID` UInt32,
`URL` String,
`EventTime` DateTime,
-- 加入布隆过滤器跳数索引,采用clickhouse提供的默认bloom_filter函数
-- 配置允许假阳性概率为0.001,官方默认值是0.025
-- 概率越小,假阳性概率越低,查询时候会有越少的颗粒发送给clickhouse引擎,所以查询速度更快,但是索引占用的磁盘空间也越多
-- 每个索引块由颗粒(granule)组成, 例如,如果主表索引粒度为8192行,GRANULARITY为4,则每个索引“块”将为32768行
-- GRANULARITY 参数配置为1就可以
INDEX skip_index_url URL TYPE bloom_filter(0.001) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY Id
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;低基数字段优化
描述
该段描述摘抄自clickhouse官方中文文档低基数类型
LowCardinality 是一种改变数据存储和数据处理方法的概念,ClickHouse会把 LowCardinality 所在的列进行字典编码,对很多应用来说,处理字典编码的数据可以显著的增加查询速度。字典编码可以参考详解LZ77字典编码压缩和解压缩流程
使用 LowCarditality 数据类型的效率依赖于数据的多样性,如果一个字典包含少于10000个不同的值,那么ClickHouse可以进行更高效的数据存储和处理,反之如果字典多于10000,效率会表现的更差。
当使用字符类型的时候,可以考虑使用 LowCardinality 代替Enum字段, LowCardinality 通常更加灵活和高效。
具体操作
现在假设需要在表里面加入Country字段,全世界总共国家总数的基数不大,如果可以的话存储为UInt8,其他低基数枚举也尽量存储为Int类型
如果Country字段是String类型,那么需要调整建表语句如下
CREATE TABLE hits_UserID_URL
(
`Id` UInt64,
-- 没有优化的时候, 类型是String,字段定义为`Country` String,
-- 优化的时候直接加上一个LowCardinality函数
-- 在已经有的表上面修改的时候不需要改动其他代码,对python, rust,golang或者其他语言的客户端代码来说,`Country`字段就是String
-- 加上LowCardinality之后,查询如果用到Country,加速效果非常明显
`Country` LowCardinality(String),
`UserID` UInt32,
`URL` String,
`EventTime` DateTime,
INDEX skip_index_url URL TYPE bloom_filter(0.001) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY Id
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;CREATE TABLE hits_UserID_URL
(
`Id` UInt64,
-- 没有优化的时候, 类型是String,字段定义为`Country` String,
-- 优化的时候直接加上一个LowCardinality函数
-- 在已经有的表上面修改的时候不需要改动其他代码,对python, rust,golang或者其他语言的客户端代码来说,`Country`字段就是String
-- 加上LowCardinality之后,查询如果用到Country,加速效果非常明显
`Country` LowCardinality(String),
`UserID` UInt32,
`URL` String,
`EventTime` DateTime,
INDEX skip_index_url URL TYPE bloom_filter(0.001) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY Id
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;注意点
LowCardinality所包含的字段不能是Int,但是配置文件中有个参数可以改变这个情况
对应配置文档如下
配置参数是allow_suspicious_low_cardinality_types
允许或限制将与固定大小为 8 字节或更少的数据类型一起使用:数字数据类型和FixedString(8_bytes_or_less).
对于小的固定值,使用 ofLowCardinality通常是低效的,因为 ClickHouse 为每一行存储一个数字索引。因此:
- 磁盘空间使用率可能会上升。
- RAM 消耗可能更高,具体取决于字典大小。
- 由于额外的编码/编码操作,某些功能可能会运行得更慢。
由于上述所有原因, MergeTree -engine表中的合并时间可能会增加。
所以遵守Clickhouse的建议,数字类型的数据就不使用LowCardinality参数了
服务器配置参数优化
如果字段索引,排序,低基数字段优化等方法都使用了,可以尝试修改一下服务器的硬件配置参数,目前发现修改服务器参数配置的查询加速效果不太明显,但是有总比没有好一点
优化项包括使用更新的内核,如果是旧内核禁止使用透明大页缓存,不要使用FAT-32或者exFAT文件系统等,从官方文档的服务器参数优化看,其实感觉真的需要去配置的只有CPU和内存方面的修改,其他的都只是一些不怎么会遇到的情况
CPU参数
很多老式的CPU由于没有睿频加速技术,所以CPU基准频率就是最高频率,修改本参数意义不大
clickhouse极大的依赖CPU运算和顺序磁盘IO的速度,所以为clickhouse配置CPU高性能模式是应该的
linux的cpu共有以下几种模式
performance: 固定工作在其支持的最高运行频率上powersave: 省电模式,固定工作在其支持的最低运行频率上Userspace: 系统将变频策略的决策权交给了用户态应用程序ondemand: 完全在内核态下工作并且能够以更加细粒度的时间间隔对系统负载情况进行采样分析并控制频率conservative: 在不影响系统性能的前提下做到更高效的节能,降频比较缓慢保守
查看当前cpu运行模式
$ sudo cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor$ sudo cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor查看cpu实际运转频率
$ sudo cat /proc/cpuinfo| grep Hz$ sudo cat /proc/cpuinfo| grep Hz设置为性能模式
$ sudo cpupower frequency-set -g performance$ sudo cpupower frequency-set -g performance或者如下命令
$ echo 'performance' | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor$ echo 'performance' | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor修改完成之后再次查看CPU频率
$ sudo cat /proc/cpuinfo| grep Hz$ sudo cat /proc/cpuinfo| grep Hzovercommit_memory配置优化
依据官方文档的描述,在机器内存小于16G的情况下,如果开启此配置,会导致很多的内存异常,所以如果机器内存小,就跳过此项配置
overcommit_memory配置是否允许过量使用内存,该参数存在原因是由于内存申请和实际内存分配使用上面存在差异,可能申请了10G内存,最终只使用了8G,存在闲置内存,程序在申请内存的时候也不是马上使用全部申请的内存,可能当真正使用的时候系统已经收回了一些内存
参数/proc/sys/vm/overcommit_memory可以控制进程对内存过量使用的应对策略,overcommit_memory可选值有以下三个
0: 允许进程轻微过量使用内存,但对于大量过载请求则不允许,也就是当内存消耗过大就是触发
OOM killer(Out Of Memory killer, 系统内存耗尽的情况下发生,干掉进程以求释放一些内存)1: 永远允许进程
overcommit,不会触发OOM killer2: 永远禁止
overcommit,不会触发OOM killer
该参数推荐配置为0
$ echo 0 | sudo tee /proc/sys/vm/overcommit_memory$ echo 0 | sudo tee /proc/sys/vm/overcommit_memory使用docker时候的优化
依据clickhouse在github仓库上面docker模块的文档描述,clickhouse存在一些高级功能,需要允许某些linux的capabilities
docker执行命令如下,发现新增了如下功能
SYS_NICE:参考, 允许修改进程的nice值,该值会影响CPU时间分片的进程调度,提高clickhouse查询语句的调度优先级NET_ADMIN: 参考, 用于收集针对查询的CPU和I/O指标IPC_LOCK:拥有锁定内存等能力
$ docker run -d \
--cap-add=SYS_NICE --cap-add=NET_ADMIN --cap-add=IPC_LOCK \
--name some-clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server$ docker run -d \
--cap-add=SYS_NICE --cap-add=NET_ADMIN --cap-add=IPC_LOCK \
--name some-clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server该配置对应与docker compose文件为
compose.yaml配置文件增加如下即可
# --snip--
image: clickhouse/clickhouse-server
ulimits:
nofile:
soft: 262144
hard: 262144
cap_add:
- SYS_NICE
- NET_ADMIN
- IPC_LOCK
# --snip--# --snip--
image: clickhouse/clickhouse-server
ulimits:
nofile:
soft: 262144
hard: 262144
cap_add:
- SYS_NICE
- NET_ADMIN
- IPC_LOCK
# --snip--这些新增的linux capabilities感觉好像对于查询语句性能来说,也没有多大的提升,但是这些毕竟是官方github推荐的,所以闭着眼睛选就可以了
clickhouse查询速度不稳定的因素
产生情况
- 如果是在数据写入之后,第一次查询某张表的数据,或者过了一段时间再次查询某张表的时候,会发现查询速度明显偏慢
主要原因
clickhouse查询的时候会把一部分数据放置在内存中,内存类型是page cache,当再次访问数据的时候,这部分数据的读取速度会保持在2-10GB/s或者更高的速度没有缓存,读取速度就取决于机器的磁盘顺序
IO速度以及CPU解压缩处理数据的速度
复现
可以通过清空
page cache的方式去重复模拟第一次查询clickhouse的速度先把
buffer缓存当中的数据同步到磁盘上面,执行如下命令shell$ sync$ sync触发回收内存操作,参数3表示清除
pagecache和slab分配器中的缓存对象shell$ echo 3 > /proc/sys/vm/drop_caches$ echo 3 > /proc/sys/vm/drop_caches最后执行如下命令查看
cache缓存的大小,主要查看cache参数的值,下面命令对应的大小是3.8Gishell$ free -wh total used free shared buffers cache available 内存: 31Gi 10Gi 16Gi 1.0Gi 14Mi 3.8Gi 18Gi 交换: 27Gi 0B 27Gi$ free -wh total used free shared buffers cache available 内存: 31Gi 10Gi 16Gi 1.0Gi 14Mi 3.8Gi 18Gi 交换: 27Gi 0B 27Gi
关于分区太小的优化建议
clickhouse推荐采用大分区,比如按照月分区,不推荐使用按照天分区,每个分区都是分开存储的,分区太多容易造成每个颗粒存储数据太分散,遇到排序的时候容易影响性能
如果查询条件是order by 分区键 limit 1,则clickhouse会从所有有效分区中加载每个分区第一个符合排序条件的颗粒,直到符合limit的要求,这样clickhouse处理的行数就大于等于 颗粒大小 * 分区数量,在分区数量确实很大的情况下,就只能减小颗粒大小。虽然clickhouse强烈建议不要更改颗粒大小,但是在业务限制必须按照按天分区的场景下,可以把颗粒大小改为更小的值,比如128,这样就可以把clickhouse引擎处理的数据行数减小到约等于原来的1/64
关于clickhouse的查询or的优化
clickhouse对于多字段的or查询不太友好,查询时候会扫描全表
TABLE UT
(
`id` UInt64
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)TABLE UT
(
`id` UInt64
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)采用上表示范,比如现在查询URL='test' 或者UserID=3的
使用一些ORM或者常规的类似于mysql的写法就是
select * from UT where URL = 'test' or UserID=3 limit 10;select * from UT where URL = 'test' or UserID=3 limit 10;上述查询就会扫描全表,把所有clickhouse颗粒发送到引擎进行查询,效率很低
这个时候需要把查询修改一下,改为如下,如果where后面的字段是存在索引的,就可以很高效的使用索引了
select * from UT where id in ( select id from UT where URL = 'test' UNION ALL select id from UT where UserID = 3)select * from UT where id in ( select id from UT where URL = 'test' UNION ALL select id from UT where UserID = 3)